EEGSampler
- class selfeeg.dataloading.load.EEGSampler(data_source: Dataset, BatchSize: int = 1, Workers: int = 0, Mode: int = 1, Keep_only_ratio: float = 1)[source]
custom pytorch Sampler designed to efficiently reduce the file loading operations.
It is designed to be combined with the
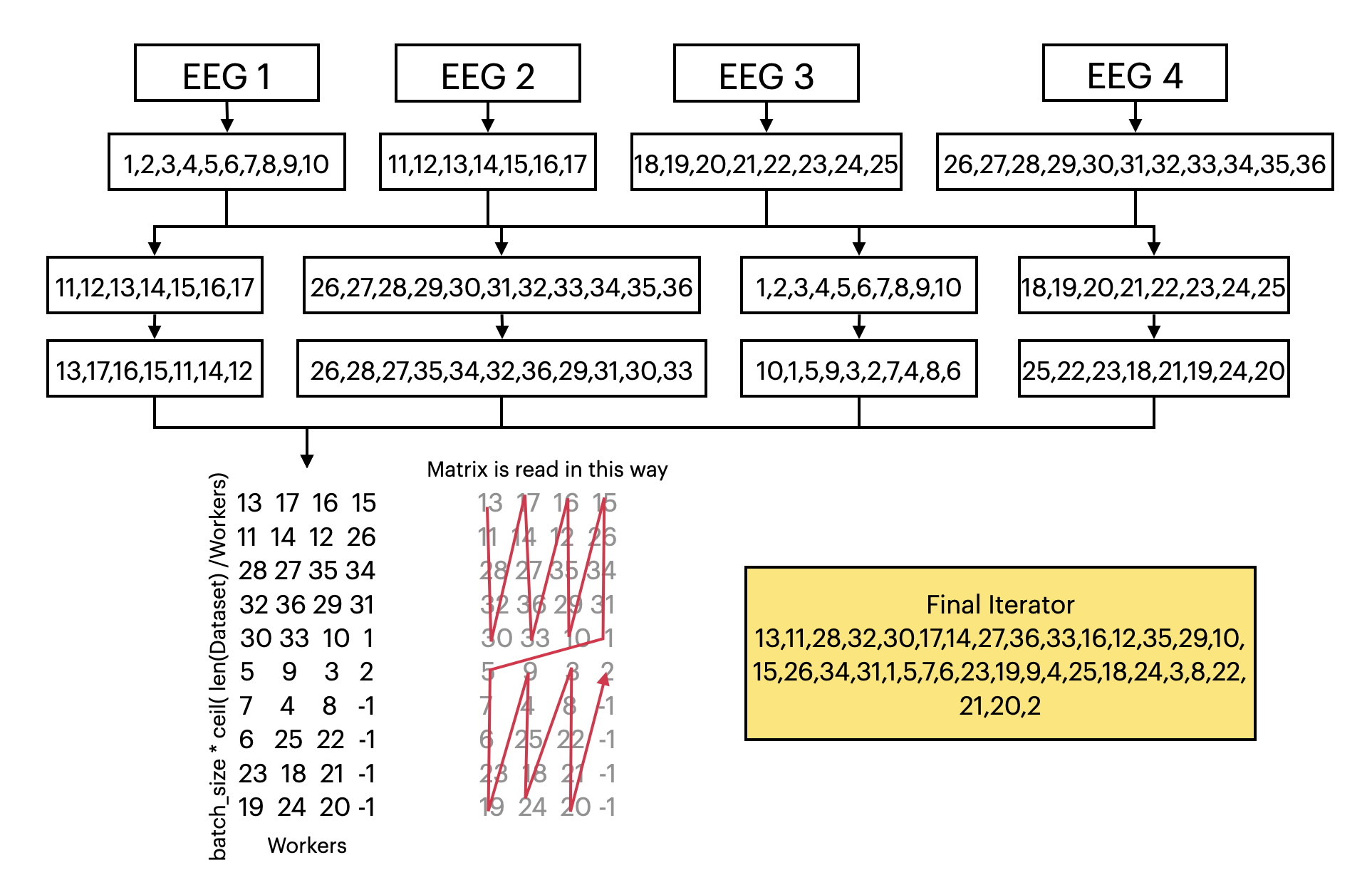
EEGDatasetclass. To do that, it exploits the parallelization properties of the pytorch Dataloader and the buffer of EEGDataset. To further check how the custom iterator is created see image reported below and check the introductory notebook provided in the documentation.- Parameters:
data_source (EEGDataset) – The instance of the
EEGdatasetclass provided in this module.BatchSize (int, optional) –
The batch size used during training. It will be used to create the custom iterator (not linear).
Default = 1
Workers (Int, optional) –
The number of workers used by the Dataloader. Must be the same as the argument workers in the Dataloader classs. It will be used to create the custom iterator (not linear).
Default = 0
Mode (int, optional) –
The mode to be used to create the iterator. It can be 0 or 1, where:
0 = the iterator is a simple linear iterator (range(0,len(dataset))
1 = the indeces are first shuffled at the inter-file level, then at the intra-file level; ultimately all indeces are rearranged based on the batch size and the number of workers in order to reduce the number of times a new EEG is loaded. The iterator can be seen as a good compromise between batch heterogeneity and batch creation speed
Default = 1
Keep_only_ratio (float, optional) –
Whether to preserve only a given ratio of samples for each files in the given EEGdataset. It can be used to reduce the training time of each epoch while being sure to feed at least a portion of each EEG file in your dataset. If not given, all samples of the given dataset will be used. Note that the sample indices will be chosen after the intra-file level shuffle so to avoid selecting the same initial portions of the EEG record.
Default = 1
Example
>>> import pickle >>> import random >>> import selfeeg.dataloading as dl >>> import selfeeg.utils >>> labels = utils.create_dataset() >>> def loadEEG(path): ... with open(path, 'rb') as handle: ... EEG = pickle.load(handle) ... x = EEG['data'] ... return x >>> random.seed(1234) >>> EEGlen = dl.get_eeg_partition_number('Simulated_EEG',freq=128, window=2, ... overlap=0.3, load_function=loadEEG ) >>> EEGsplit = dl.get_eeg_split_table(EEGlen, seed=1234) #default 60/20/20 ratio >>> TrainSet = dl.EEGDataset(EEGlen,EEGsplit,[128,2,0.3],load_function=loadEEG) >>> smplr = EEGSampler(TrainSet, 16, 8) >>> print([i for i in a][:8]) ... # will return [599, 1661, 1354, 1942, 1907, 495, 489, 1013]
This image summarizes how the custom sampler iterator is created: